A Comprehensive Review of Speech Emotion Recognition Systems
Ieee account.
- Change Username/Password
- Update Address

Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
Help | Advanced Search
Electrical Engineering and Systems Science > Audio and Speech Processing
Title: recent advances in end-to-end automatic speech recognition.
Abstract: Recently, the speech community is seeing a significant trend of moving from deep neural network based hybrid modeling to end-to-end (E2E) modeling for automatic speech recognition (ASR). While E2E models achieve the state-of-the-art results in most benchmarks in terms of ASR accuracy, hybrid models are still used in a large proportion of commercial ASR systems at the current time. There are lots of practical factors that affect the production model deployment decision. Traditional hybrid models, being optimized for production for decades, are usually good at these factors. Without providing excellent solutions to all these factors, it is hard for E2E models to be widely commercialized. In this paper, we will overview the recent advances in E2E models, focusing on technologies addressing those challenges from the industry's perspective.
Submission history
Access paper:.
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
speech recognition Recently Published Documents
Total documents.
- Latest Documents
- Most Cited Documents
- Contributed Authors
- Related Sources
- Related Keywords
Improving Deep Learning based Automatic Speech Recognition for Gujarati
We present a novel approach for improving the performance of an End-to-End speech recognition system for the Gujarati language. We follow a deep learning-based approach that includes Convolutional Neural Network, Bi-directional Long Short Term Memory layers, Dense layers, and Connectionist Temporal Classification as a loss function. To improve the performance of the system with the limited size of the dataset, we present a combined language model (Word-level language Model and Character-level language model)-based prefix decoding technique and Bidirectional Encoder Representations from Transformers-based post-processing technique. To gain key insights from our Automatic Speech Recognition (ASR) system, we used the inferences from the system and proposed different analysis methods. These insights help us in understanding and improving the ASR system as well as provide intuition into the language used for the ASR system. We have trained the model on the Microsoft Speech Corpus, and we observe a 5.87% decrease in Word Error Rate (WER) with respect to base-model WER.
Dereverberation of autoregressive envelopes for far-field speech recognition
A computational look at oral history archives.
Computational technologies have revolutionized the archival sciences field, prompting new approaches to process the extensive data in these collections. Automatic speech recognition and natural language processing create unique possibilities for analysis of oral history (OH) interviews, where otherwise the transcription and analysis of the full recording would be too time consuming. However, many oral historians note the loss of aural information when converting the speech into text, pointing out the relevance of subjective cues for a full understanding of the interviewee narrative. In this article, we explore various computational technologies for social signal processing and their potential application space in OH archives, as well as neighboring domains where qualitative studies is a frequently used method. We also highlight the latest developments in key technologies for multimedia archiving practices such as natural language processing and automatic speech recognition. We discuss the analysis of both visual (body language and facial expressions), and non-visual cues (paralinguistics, breathing, and heart rate), stating the specific challenges introduced by the characteristics of OH collections. We argue that applying social signal processing to OH archives will have a wider influence than solely OH practices, bringing benefits for various fields from humanities to computer sciences, as well as to archival sciences. Looking at human emotions and somatic reactions on extensive interview collections would give scholars from multiple fields the opportunity to focus on feelings, mood, culture, and subjective experiences expressed in these interviews on a larger scale.
Contribution of frequency compressed temporal fine structure cues to the speech recognition in noise: An implication in cochlear implant signal processing
Supplemental material for song properties and familiarity affect speech recognition in musical noise, noise-robust speech recognition in mobile network based on convolution neural networks, optical laser microphone for human-robot interaction: speech recognition in extremely noisy service environments, improving low-resource tibetan end-to-end asr by multilingual and multilevel unit modeling.
AbstractConventional automatic speech recognition (ASR) and emerging end-to-end (E2E) speech recognition have achieved promising results after being provided with sufficient resources. However, for low-resource language, the current ASR is still challenging. The Lhasa dialect is the most widespread Tibetan dialect and has a wealth of speakers and transcriptions. Hence, it is meaningful to apply the ASR technique to the Lhasa dialect for historical heritage protection and cultural exchange. Previous work on Tibetan speech recognition focused on selecting phone-level acoustic modeling units and incorporating tonal information but underestimated the influence of limited data. The purpose of this paper is to improve the speech recognition performance of the low-resource Lhasa dialect by adopting multilingual speech recognition technology on the E2E structure based on the transfer learning framework. Using transfer learning, we first establish a monolingual E2E ASR system for the Lhasa dialect with different source languages to initialize the ASR model to compare the positive effects of source languages on the Tibetan ASR model. We further propose a multilingual E2E ASR system by utilizing initialization strategies with different source languages and multilevel units, which is proposed for the first time. Our experiments show that the performance of the proposed method-based ASR system exceeds that of the E2E baseline ASR system. Our proposed method effectively models the low-resource Lhasa dialect and achieves a relative 14.2% performance improvement in character error rate (CER) compared to DNN-HMM systems. Moreover, from the best monolingual E2E model to the best multilingual E2E model of the Lhasa dialect, the system’s performance increased by 8.4% in CER.
Background Speech Synchronous Recognition Method of E-commerce Platform Based on Hidden Markov Model
In order to improve the effect of e-commerce platform background speech synchronous recognition and solve the problem that traditional methods are vulnerable to sudden noise, resulting in poor recognition effect, this paper proposes a background speech synchronous recognition method based on Hidden Markov model. Combined with the principle of speech recognition, the speech feature is collected. Hidden Markov model is used to input and recognize high fidelity speech filter to ensure the effectiveness of signal processing results. Through the de-noising of e-commerce platform background voice, and the language signal cache and storage recognition, using vector graph buffer audio, through the Ethernet interface transplant related speech recognition sequence, thus realizing background speech synchronization, so as to realize the language recognition, improve the recognition accuracy. Finally, the experimental results show that the background speech synchronous recognition method based on Hidden Markov model is better than the traditional methods.
Massive Speech Recognition Resource Scheduling System based on Grid Computing
Nowadays, there are too many large-scale speech recognition resources, which makes it difficult to ensure the scheduling speed and accuracy. In order to improve the effect of large-scale speech recognition resource scheduling, a large-scale speech recognition resource scheduling system based on grid computing is designed in this paper. In the hardware part, microprocessor, Ethernet control chip, controller and acquisition card are designed. In the software part of the system, it mainly carries out the retrieval and exchange of information resources, so as to realize the information scheduling of the same type of large-scale speech recognition resources. The experimental results show that the information scheduling time of the designed system is short, up to 2.4min, and the scheduling accuracy is high, up to 90%, in order to provide some help to effectively improve the speed and accuracy of information scheduling.
Export Citation Format
Share document.
Advertisement
A comprehensive survey on automatic speech recognition using neural networks
- Published: 15 August 2023
- Volume 83 , pages 23367–23412, ( 2024 )
Cite this article

- Amandeep Singh Dhanjal ORCID: orcid.org/0000-0002-7763-9174 1 &
- Williamjeet Singh 2
2337 Accesses
15 Citations
Explore all metrics
The continuous development in Automatic Speech Recognition has grown and demonstrated its enormous potential in Human Interaction Communication systems. It is quite a challenging task to achieve high accuracy due to several parameters such as different dialects, spontaneous speech, speaker’s enrolment, computation power, dataset, and noisy environment that decrease the performance of the speech recognition system. It has motivated various researchers to make innovative contributions to the development of a robust speech recognition system. The study presents a systematic analysis of current state-of-the-art research work done in this field during 2015-2021. The prime focus of the study is to highlight the neural network-based speech recognition techniques, datasets, toolkits, and evaluation metrics utilized in the past seven years. It also synthesizes the evidence from past studies to provide empirical solutions for accuracy improvement. This study highlights the current status of speech recognition systems using neural networks and provides a brief knowledge to the new researchers.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

Automatic speech recognition: a survey

ANNs for Automatic Speech Recognition—A Survey

State-of-the-Art Review on Recent Trends in Automatic Speech Recognition
Explore related subjects.
- Artificial Intelligence
Dataset availability
The datasets analysed during the current study are available in the respective articles. For more detail please check Table 11
Abdel-Hamid O, Mohamed A-r, Jiang H, Deng L, Penn G, Yu D (2014) Convolutional Neural Networks for Speech Recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing 22(10):1533–1545. https://doi.org/10.1109/TASLP.2014.2339736
Article Google Scholar
Abed S, Mohd BJ, Al Shayeji MH (2019) Implementation of speech feature extraction for low-resource devices. IET Circuits, Devices and Systems 13(6):863–872. https://doi.org/10.1049/iet-cds.2018.5225
Addarrazi I, Satori H, Satori K (2018) Building a first amazigh database for automatic audiovisual speech recognition system. ACM International Conference Proceeding Series 94–99. https://doi.org/10.1145/3289100.3289116
Jin Y, Wen B, Gu Z, Jiang X, Shu X, Zeng Z, Zhang Y, Guo Z, Chen Y, Zheng T, Yue Y, Zhang H, Ding H (2020) Deep-Learning-Enabled MXene-Based Artificial Throat: Toward Sound Detection and Speech Recognition. Advanced Materials Technologies 5(9): 2000262. https://doi.org/10.1002/admt.202000262
Padmanabhan J, Johnson Premkumar MJ (2015) Machine Learning in Automatic Speech Recognition: A Survey. IETE Technical Review 32(4): 240–251. https://doi.org/10.1080/02564602.2015.1010611
Aguiar de Lima T, Da Costa-Abreu M (2020) A survey on automatic speech recognition systems for Portuguese language and its variations. Computer Speech and Language 62:1–64. https://doi.org/10.1016/j.csl.2019.101055
Alam M, Samad MD, Vidyaratne L, Glandon A, Iftekharuddin KM (2020) Survey on Deep Neural Networks in Speech and Vision Systems. Neurocomputing 417(5):302–321. https://doi.org/10.1016/j.neucom.2020.07.053
Article CAS PubMed PubMed Central Google Scholar
Dargan S, Kumar M, Ayyagari MR, Kumar G (2020) A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Archives of Computational Methods in Engineering 27(4): 1071–1092. https://doi.org/10.1007/s11831-019-09344-w
Ayo FE, Folorunso O, Ibharalu FT, Osinuga IA (2020) Machine learning techniques for hate speech classification of twitter data: State-of-The-Art, future challenges and research directions. Computer Science Review 38:1–34. https://doi.org/10.1016/j.cosrev.2020.100311
Azarang A, Kehtarnavaz N (2020) A review of multi-objective deep learning speech denoising methods. Speech Communication 122(February):1–10. https://doi.org/10.1016/j.specom.2020.04.002
Goh YH, Raveendran P, Goh YL (2015) Robust speech recognition system using bidirectional Kalman filter. IET Signal Processing 9(6): 491–497. https://doi.org/10.1049/iet-spr.2014.0109
Bang J-U, Yun S, Kim S-H, Choi M-Y, Lee M-K, Kim Y-J, Kim D-H, Park J, Lee Y-J, Kim S-H (2020) KsponSpeech: Korean Spontaneous Speech Corpus for Automatic Speech Recognition. Applied Sciences 10(19):1–17. https://doi.org/10.3390/app10196936
Article CAS Google Scholar
Singh A, Kadyan V, Kumar M, Bassan N (2020) ASRoIL: a Comprehensive Survey for Automatic Speech Recognition of Indian Languages vol. 53 pp. 3673–3704. Springer ???. https://doi.org/10.1007/s10462-019-09775-8
Becerra A, de la Rosa JI, González E, Pedroza AD, Escalante NI, Santos E (2020) A comparative case study of neural network training by using frame-level cost functions for automatic speech recognition purposes in Spanish. Multimedia Tools and Applications 79(27–28):19669–19715. https://doi.org/10.1007/s11042-020-08782-0
Bhatt S, Dev A, Jain A (2020) Confusion analysis in phoneme based speech recognition in Hindi. Journal of Ambient Intelligence and Humanized Computing 11(10):4213–4238. https://doi.org/10.1007/s12652-020-01703-x
Bhatt S, Jain A, Dev A (2020) Syllable based Hindi speech recognition. J Inf Optim Sci 41(6):1–20. https://doi.org/10.1080/02522667.2020.1809091
Bingol MC, Aydogmus O (2020) Performing predefined tasks using the human-robot interaction on speech recognition for an industrial robot. Eng Appl Artif Intell 95(August):103903. https://doi.org/10.1016/j.engappai.2020.103903
Bird JJ, Wanner E, Ekárt A, Faria DR (2020) Optimisation of phonetic aware speech recognition through multi-objective evolutionary algorithms. Expert Systems with Applications 153:113402. https://doi.org/10.1016/j.eswa.2020.113402
Cai M, Liu J (2016) Maxout neurons for deep convolutional and LSTM neural networks in speech recognition. Speech Communication 77:53–64. https://doi.org/10.1016/j.specom.2015.12.003
Caranica A, Cucu H, Buzo A, Burileanu C (2016) On the design of an automatic speech recognition system for Romanian language. Control Engineering and Applied Informatics 18(2):65–76
Google Scholar
Keshet J (2018) Automatic speech recognition: A primer for speech-language pathology researchers. International Journal of Speech-Language Pathology 20(6): 599–609. https://doi.org/10.1080/17549507.2018.1510033
Cheng G, Li X, Yan Y (2019) Using Highway Connections to Enable Deep Small-footprint LSTM-RNNs for Speech Recognition. Chin J Electron 28(1):107–112. https://doi.org/10.1049/cje.2018.11.008
Kaur J, Singh A, Kadyan V (2020) Automatic Speech Recognition System for Tonal Languages: State-of-the-Art Survey. Archives of Computational Methods in Engineering (0123456789). https://doi.org/10.1007/s11831-020-09414-4
Uma Maheswari S, Shahina A, Nayeemulla Khan A (2021) Understanding Lombard speech: a review of compensation techniques towards improving speech based recognition systems. Artif Intell Rev 54(4): 2495–2523. https://doi.org/10.1007/s10462-020-09907-5
Darabkh KA, Haddad L, Sweidan SZ, Hawa M, Saifan R, Alnabelsi SH (2018) An efficient speech recognition system for arm-disabled students based on isolated words. Computer Applications in Engineering Education 26(2):285–301. https://doi.org/10.1002/cae.21884
Dargan S, Kumar M, Ayyagari MR, Kumar G (2020) A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Archives of Computational Methods in Engineering 27(4):1071–1092. https://doi.org/10.1007/s11831-019-09344-w
Article MathSciNet Google Scholar
Deepa P, Khilar R (2022) Speech technology in healthcare. Measurement: Sensors 24(August):100565. https://doi.org/10.1016/j.measen.2022.100565
Muhammad AN, Aseere AM, Chiroma H, Shah H, Gital AY, Hashem IAT (2021) Deep Learning Application in Smart Cities: Recent Development, Taxonomy, Challenges and Research Prospects vol. 33 pp. 2973–3009. Springer ???. https://doi.org/10.1007/s00521-020-05151-8
El Hannani A, Errattahi R, Salmam FZ, Hain T, Ouahmane H (2021) Evaluation of the effectiveness and efficiency of state-of-the-art features and models for automatic speech recognition error detection. Journal of Big Data 8(1):1–16. https://doi.org/10.1186/s40537-020-00391-w
El-Moneim SA, Nassar MA, Dessouky MI, Ismail NA, El-Fishawy AS, Abd El-Samie FE (2020) Text-independent speaker recognition using LSTM-RNN and speech enhancement. Multimedia Tools and Applications 79(33–34):24013–24028. https://doi.org/10.1007/s11042-019-08293-7
Patel H, Thakkar A, Pandya M, Makwana K (2018) Neural network with deep learning architectures. J Inf Optim Sci39(1): 31–38. https://doi.org/10.1080/02522667.2017.1372908
Frihia H, Bahi H (2017) HMM/SVM segmentation and labelling of Arabic speech for speech recognition applications. International Journal of Speech Technology 20(3):563–573. https://doi.org/10.1007/s10772-017-9427-z
Khan A, Sohail A, Zahoora U, Qureshi AS (2020) A Survey of the Recent Architectures of Deep Convolutional Neural Networks vol. 53 pp. 5455–5516. Springer ???. https://doi.org/10.1007/s10462-020-09825-6
Garain A, Singh PK, Sarkar R (2021) FuzzyGCP: A deep learning architecture for automatic spoken language identification from speech signals. Expert Systems with Applications 168:1–14. https://doi.org/10.1016/j.eswa.2020.114416
Goh YH, Raveendran P, Goh YL (2015) Robust speech recognition system using bidirectional Kalman filter. IET Signal Processing 9(6):491–497. https://doi.org/10.1049/iet-spr.2014.0109
Golda Brunet R, Hema Murthy A (2018) Transcription Correction Using Group Delay Processing for Continuous Speech Recognition. Circuits, Systems, and Signal Processing 37(3):1177–1202. https://doi.org/10.1007/s00034-017-0598-2
Zhu T, Cheng C (2020) Joint CTC-Attention End-to-End Speech Recognition with a Triangle Recurrent Neural Network Encoder. Journal of Shanghai Jiaotong University (Science) 25(1): 70–75. https://doi.org/10.1007/s12204-019-2147-6
Guerid A, Houacine A (2019) Recognition of isolated digits using DNN-HMM and harmonic noise model. IET Signal Processing 13(2):207–214. https://doi.org/10.1049/iet-spr.2018.5131
Gurunath Shivakumar P, Georgiou P (2020) Transfer learning from adult to children for speech recognition: Evaluation, analysis and recommendations. Computer Speech and Language 63:1–21. https://doi.org/10.1016/j.csl.2020.101077
Donkers T, Loepp B, Ziegler J (2017) Sequential User-based Recurrent Neural Network Recommendations. In: Proceedings of the Eleventh ACM Conference on Recommender Systems pp. 152–160. ACM New York, NY, USA. https://doi.org/10.1145/3109859.3109877
Kang J, Zhang W-Q, Liu W-W, Liu J, Johnson MT (2018) Advanced recurrent network-based hybrid acoustic models for low resource speech recognition. EURASIP Journal on Audio, Speech, and Music Processing 6(1): 1–15. https://doi.org/10.1186/s13636-018-0128-6
Hou J, Guo W, Song Y (2020) Dai L-R (2020) Segment boundary detection directed attention for online end-to-end speech recognition. EURASIP Journal on Audio, Speech, and Music Processing 1:3. https://doi.org/10.1186/s13636-020-0170-z
CHENG G, LI X, YAN Y (2019) Using Highway Connections to Enable Deep Small-footprint LSTM-RNNs for Speech Recognition. Chin J Electron 28(1): 107–112. https://doi.org/10.1049/cje.2018.11.008
Ayo FE, Folorunso O, Ibharalu FT, Osinuga IA (2020) Machine learning techniques for hate speech classification of twitter data: State-of-The-Art, future challenges and research directions. Computer Science Review 38 1–34. https://doi.org/10.1016/j.cosrev.2020.100311
Jahangir R, Teh YW, Hanif F, Mujtaba G (2021) Deep learning approaches for speech emotion recognition: State of the art and research challenges. Multimedia Tools and Applications 1–66. https://doi.org/10.1007/s11042-020-09874-7
Jermsittiparsert K, Abdurrahman A, Siriattakul P, Sundeeva LA, Hashim W, Rahim R, Maseleno A (2020) Pattern recognition and features selection for speech emotion recognition model using deep learning. International Journal of Speech Technology 23(4):799–806. https://doi.org/10.1007/s10772-020-09690-2
Jin Y, Wen B, Gu Z, Jiang X, Shu X, Zeng Z, Zhang Y, Guo Z, Chen Y, Zheng T, Yue Y, Zhang H, Ding H (2020) Deep-Learning-Enabled MXene-Based Artificial Throat: Toward Sound Detection and Speech Recognition. Advanced Materials Technologies 5(9):2000262. https://doi.org/10.1002/admt.202000262
Kadyan V, Mantri A, Aggarwal RK (2018) Refinement of HMM Model Parameters for Punjabi Automatic Speech Recognition (PASR) System. IETE Journal of Research 64(5):1–16. https://doi.org/10.1080/03772063.2017.1369370
Kadyan V, Dua M, Dhiman P (2021) Enhancing accuracy of long contextual dependencies for Punjabi speech recognition system using deep LSTM. International Journal of Speech Technology 24(2):517–527. https://doi.org/10.1007/s10772-021-09814-2
Kalamani M, Krishnamoorthi M, Valarmathi RS (2019) Continuous Tamil Speech Recognition technique under non stationary noisy environments. International Journal of Speech Technology 22(1):47–58. https://doi.org/10.1007/s10772-018-09580-8
Kang J, Zhang W-Q, Liu W-W, Liu J, Johnson MT (2018) Advanced recurrent network-based hybrid acoustic models for low resource speech recognition. EURASIP Journal on Audio, Speech, and Music Processing 6(1):1–15. https://doi.org/10.1186/s13636-018-0128-6
Wang J (2020) Speech recognition in English cultural promotion via recurrent neural network. Pers Ubiquit Comput 24(2): 237–246. https://doi.org/10.1007/s00779-019-01293-2
Watanabe S, Hori T, Karita S, Hayashi T, Nishitoba J, Unno Y, Enrique Yalta Soplin N, Heymann J, Wiesner M, Chen N, Renduchintala A, Ochiai T (2018) ESPnet: End-to-End Speech Processing Toolkit. In: Interspeech 2018 pp. 2207–2211. ISCA ISCA. https://doi.org/10.21437/Interspeech.2018-1456 . http://arxiv.org/abs/1804.00015 http://www.isca-speech.org/archive/Interspeech_2018/abstracts/1456.html
Keshet J (2018) Automatic speech recognition: A primer for speech-language pathology researchers. International Journal of Speech-Language Pathology 20(6):599–609. https://doi.org/10.1080/17549507.2018.1510033
Article PubMed Google Scholar
Bang J.-U, Yun S, Kim S-H, Choi M-Y, Lee M-K, Kim Y-J, Kim D-H, Park J, Lee Y-J, Kim S-H (2020) KsponSpeech: Korean Spontaneous Speech Corpus for Automatic Speech Recognition. Applied Sciences 10(19): 1–17. https://doi.org/10.3390/app10196936
Kim D, Kim S (2019) Fast speaker adaptation using extended diagonal linear transformation for deep neural networks. ETRI Journal 41(1):109–116. https://doi.org/10.4218/etrij.2017-0087
Article ADS Google Scholar
Kim S, Bae S, Won C (2021) Open-source toolkit for end-to-end Korean speech recognition. Software Impacts 7:1–4. https://doi.org/10.1016/j.simpa.2021.100054
Han Z, Zhao H, Wang R (2019) Transfer Learning for Speech Emotion Recognition. In: 2019 IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS) pp. 96–99. IEEE ???. https://doi.org/10.1109/BigDataSecurity-HPSC-IDS.2019.00027 . https://ieeexplore.ieee.org/document/8818976/
Kipyatkova IS, Karpov AA (2017) A study of neural network Russian language models for automatic continuous speech recognition systems. Autom Remote Control 78(5):858–867. https://doi.org/10.1134/S0005117917050083
Kitaoka N, Chen B, Obashi Y (2021) Dynamic out-of-vocabulary word registration to language model for speech recognition. Eurasip Journal on Audio, Speech, and Music Processing 2021(1):1–8. https://doi.org/10.1186/s13636-020-00193-1
Kumar Y, Singh N, Kumar M, Singh A (2021) AutoSSR: an efficient approach for automatic spontaneous speech recognition model for the Punjabi Language. Soft Computing 25(2):1617–1630. https://doi.org/10.1007/s00500-020-05248-1
Song Z (2020) English speech recognition based on deep learning with multiple features. Computing 102(3): 663–682. https://doi.org/10.1007/s00607-019-00753-0
Tóth L (2015) Phone recognition with hierarchical convolutional deep maxout networks. EURASIP Journal on Audio, Speech, and Music Processing 25(1): 1–13. https://doi.org/10.1186/s13636-015-0068-3
Le Prell CG, Clavier OH (2017) Effects of noise on speech recognition: Challenges for communication by service members. Hearing Research 349:76–89. https://doi.org/10.1016/j.heares.2016.10.004
Lee S, Chang JH (2017) Spectral difference for statistical model-based speech enhancement in speech recognition. Multimedia Tools and Applications 76(23):24917–24929. https://doi.org/10.1007/s11042-016-4122-7
Lekshmi KR, Sherly E (2021) An acoustic model and linguistic analysis for Malayalam disyllabic words: a low resource language. International Journal of Speech Technology 24(2):483–495. https://doi.org/10.1007/s10772-021-09807-1
Li Z, Ming Y, Yang L, Xue J-H (2021) Mutual-learning sequence-level knowledge distillation for automatic speech recognition. Neurocomputing 428:259–267. https://doi.org/10.1016/j.neucom.2020.11.025
Passricha V, Aggarwal RK (2020) A comparative analysis of pooling strategies for convolutional neural network based Hindi ASR. Journal of Ambient Intelligence and Humanized Computing 11(2): 675–691. https://doi.org/10.1007/s12652-019-01325-y
Cai M, Liu J (2016) Maxout neurons for deep convolutional and LSTM neural networks in speech recognition. Speech Communication 77, 53–64. https://doi.org/10.1016/j.specom.2015.12.003
Bingol MC, Aydogmus O (2020) Performing predefined tasks using the human-robot interaction on speech recognition for an industrial robot. Eng Appl Artif Intell 95(August): 103903. https://doi.org/10.1016/j.engappai.2020.103903
Magnuson JS, You H, Luthra S, Li M, Nam H, Escabí M, Brown K, Allopenna PD, Theodore RM, Monto N, Rueckl JG (2020) EARSHOT: A Minimal Neural Network Model of Incremental Human Speech Recognition. Cognitive Science 44(4):1–17. https://doi.org/10.1111/cogs.12823
Zia T, Zahid U (2019) Long short-term memory recurrent neural network architectures for Urdu acoustic modeling. International Journal of Speech Technology 22(1): 21–30. https://doi.org/10.1007/s10772-018-09573-7
Zhang Y, Zhang P, Yan Y (2019) Language Model Score Regularization for Speech Recognition. Chin J Electron 28(3): 604–609. https://doi.org/10.1049/cje.2019.03.015
Hou J, Guo W, Song Y, Dai L-R (2020) Segment boundary detection directed attention for online end-to-end speech recognition. EURASIP Journal on Audio, Speech, and Music Processing 2020(1): 3. https://doi.org/10.1186/s13636-020-0170-z
Ogunfunmi T, Ramachandran RP, Togneri R, Zhao Y, Xia X (2019) A Primer on Deep Learning Architectures and Applications in Speech Processing. Circuits, Systems, and Signal Processing 38(8):3406–3432. https://doi.org/10.1007/s00034-019-01157-3
Orken M, Dina O, Keylan A, Tolganay T, Mohamed O (2022) A study of transformer-based end-to-end speech recognition system for Kazakh language. Scientific Reports 12(1):1–11. https://doi.org/10.1038/s41598-022-12260-y
Padmanabhan J, Johnson Premkumar MJ (2015) Machine Learning in Automatic Speech Recognition: A Survey. IETE Technical Review 32(4):240–251. https://doi.org/10.1080/02564602.2015.1010611
Palaz D, Magimai-Doss M, Collobert R (2019) End-to-end acoustic modeling using convolutional neural networks for HMM-based automatic speech recognition. Speech Communication 108(January):15–32. https://doi.org/10.1016/j.specom.2019.01.004
Pan H, Niu X, Li R, Dou Y, Jiang H (2020) Annealed gradient descent for deep learning. Neurocomputing 380:201–211. https://doi.org/10.1016/j.neucom.2019.11.021
Passricha V, Aggarwal RK (2019) Convolutional support vector machines for speech recognition. International Journal of Speech Technology 22(3):601–609. https://doi.org/10.1007/s10772-018-09584-4
Passricha V, Aggarwal RK (2020) A comparative analysis of pooling strategies for convolutional neural network based Hindi ASR. Journal of Ambient Intelligence and Humanized Computing 11(2):675–691. https://doi.org/10.1007/s12652-019-01325-y
Ravanelli M, Omologo M (2018) Automatic context window composition for distant speech recognition. Speech Communication 101, 34–44. https://doi.org/10.1016/j.specom.2018.05.001 arXiv:1805.10498
Patel H, Thakkar A, Pandya M, Makwana K (2018) Neural network with deep learning architectures. J Inf Optim Sci 39(1):31–38. https://doi.org/10.1080/02522667.2017.1372908
Pawar MD, Kokate RD (2021) Convolution neural network based automatic speech emotion recognition using Mel-frequency Cepstrum coefficients. Multimedia Tools and Applications 80(10):15563–15587. https://doi.org/10.1007/s11042-020-10329-2
Li R, Wang X, Mallidi SH, Watanabe S, Hori T, Hermansky H (2020) Multi-Stream End-to-End Speech Recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing 28(8): 646–655 arXiv:1906.08041 . https://doi.org/10.1109/TASLP.2019.2959721
Yoon JW, Woo BJ, Ahn S, Lee H, Kim NS (2022) Inter-KD: Intermediate Knowledge Distillation for CTC-Based Automatic Speech Recognition. In: 2022 IEEE Spoken Language Technology Workshop (SLT) pp. 280–286. IEEE ???. https://doi.org/10.1109/SLT54892.2023.10022581 . https://ieeexplore.ieee.org/document/10022581/
Pironkov G, Wood SU, Dupont S (2020) Hybrid-task learning for robust automatic speech recognition. Computer Speech and Language 64:101103. https://doi.org/10.1016/j.csl.2020.101103
Praveen Kumar PS, Thimmaraja Yadava G, Jayanna HS (2020) Continuous Kannada Speech Recognition System Under Degraded Condition. Circuits, Systems, and Signal Processing 39(1):391–419. https://doi.org/10.1007/s00034-019-01189-9
Qian Y, Hu H, Tan T (2019) Data augmentation using generative adversarial networks for robust speech recognition. Speech Communication 114(January):1–9. https://doi.org/10.1016/j.specom.2019.08.006
Zoughi T, Homayounpour MM (2019) A Gender-Aware Deep Neural Network Structure for Speech Recognition. Iranian Journal of Science and Technology, Transactions of Electrical Engineering 43(3): 1–10. https://doi.org/10.1007/s40998-019-00177-8
Praveen Kumar PS, Thimmaraja Yadava G, Jayanna HS (2020) Continuous Kannada Speech Recognition System Under Degraded Condition. Circuits, Systems, and Signal Processing 39(1): 391–419. https://doi.org/10.1007/s00034-019-01189-9
Qin C-X, Qu D (2018) Zhang L-H (2018) Towards end-to-end speech recognition with transfer learning. EURASIP Journal on Audio, Speech, and Music Processing 1:18. https://doi.org/10.1186/s13636-018-0141-9
Radzikowski K, Wang L, Yoshie O (2021) Nowak R (2021) Accent modification for speech recognition of non-native speakers using neural style transfer. EURASIP Journal on Audio, Speech, and Music Processing 1:11. https://doi.org/10.1186/s13636-021-00199-3
Rahmani MH, Almasganj F, Seyyedsalehi SA (2018) Audio-visual feature fusion via deep neural networks for automatic speech recognition. Digital Signal Processing: A Review Journal 82:54–63. https://doi.org/10.1016/j.dsp.2018.06.004
Rajendran S, Jayagopal P (2020) Preserving learnability and intelligibility at the point of care with assimilation of different speech recognition techniques. International Journal of Speech Technology 23(2):265–276. https://doi.org/10.1007/s10772-020-09687-x
Ramteke PB, Supanekar S, Koolagudi SG (2020) Classification of aspirated and unaspirated sounds in speech using excitation and signal level information. Computer Speech and Language 62:1–18. https://doi.org/10.1016/j.csl.2019.101057
Ravanelli M, Brakel P, Omologo M, Bengio Y (2018) Light Gated Recurrent Units for Speech Recognition. IEEE Transactions on Emerging Topics in Computational Intelligence 2(2):92–102. https://doi.org/10.1109/TETCI.2017.2762739
Garain A, Singh PK, Sarkar R (2021) FuzzyGCP: A deep learning architecture for automatic spoken language identification from speech signals. Expert Systems with Applications 168(June 2020): 1–14. https://doi.org/10.1016/j.eswa.2020.114416
Sabzi Shahrebabaki A, Imran AS, Olfati N, Svendsen T (2019) A Comparative Study of Deep Learning Techniques on Frame-Level Speech Data Classification. Circuits, Systems, and Signal Processing 38(8):3501–3520. https://doi.org/10.1007/s00034-019-01130-0
Li Z, Ming Y, Yang L, Xue J-H (2021) Mutual-learning sequence-level knowledge distillation for automatic speech recognition. Neurocomputing 428, 259–267. https://doi.org/10.1016/j.neucom.2020.11.025
Tong R, Wang L, Ma B (2017) Transfer learning for children’s speech recognition. In: 2017 International Conference on Asian Language Processing (IALP) vol. 2018-Janua pp. 36–39. IEEE ???. https://doi.org/10.1109/IALP.2017.8300540 . http://ieeexplore.ieee.org/document/8300540/
Saifan RR, Dweik W, Abdel-Majeed M (2018) A machine learning based deaf assistance digital system. Comput Appl Eng Educ 26(4):1008–1019. https://doi.org/10.1002/cae.21952
Liu D, Mao Q, Wang Z (2020) Keyword retrieving in continuous speech using connectionist temporal classification. Journal of Ambient Intelligence and Humanized Computing (0123456789). https://doi.org/10.1007/s12652-020-01933-z
Becerra A, de la Rosa JI, González E, Pedroza AD, Escalante NI, Santos E (2020) A comparative case study of neural network training by using frame-level cost functions for automatic speech recognition purposes in Spanish. Multimedia Tools and Applications 79(27-28): 19669–19715. https://doi.org/10.1007/s11042-020-08782-0
Sarma BD, Prasanna SRM (2018) Acoustic-Phonetic Analysis for Speech Recognition: A Review. IETE Technical Review 35(3):1–24. https://doi.org/10.1080/02564602.2017.1293570
Mikolov T, Kombrink S, Burget L, Cernocky J, Khudanpur S (2011) Extensions of recurrent neural network language model. In: 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) pp. 5528–5531. IEEE ???. https://doi.org/10.1109/ICASSP.2011.5947611 . http://ieeexplore.ieee.org/document/5947611/
Shi Y, Zhang W-Q, Liu J, Johnson MT (2013) RNN language model with word clustering and class-based output layer. EURASIP Journal on Audio, Speech, and Music Processing 2013(1): 22. https://doi.org/10.1186/1687-4722-2013-22
Sharma V, Mir RN (2020) A comprehensive and systematic look up into deep learning based object detection techniques: A review. Computer Science Review 38:1–29. https://doi.org/10.1016/j.cosrev.2020.100301
Sharma M, Sarma KK (2017) Soft computation based spectral and temporal models of linguistically motivated Assamese telephonic conversation recognition. CSI Transactions on ICT 5(2):209–216. https://doi.org/10.1007/s40012-016-0145-5
Sharma N, Sharma R, Jindal N (2021) Machine Learning and Deep Learning Applications-A Vision. Global Transitions Proceedings 2(1):24–28. https://doi.org/10.1016/j.gltp.2021.01.004
Sharmin R, Rahut SK, Huq MR (2020) Bengali Spoken Digit Classification: A Deep Learning Approach Using Convolutional Neural Network. Procedia Computer Science 171(2019):1381–1388. https://doi.org/10.1016/j.procs.2020.04.148
Shi Y, Zhang W-Q, Liu J (2013) Johnson MT (2013) RNN language model with word clustering and class-based output layer. EURASIP Journal on Audio, Speech, and Music Processing 1:22. https://doi.org/10.1186/1687-4722-2013-22
Wellsandt S, Foosherian M, Thoben K-D (2020) Interacting with a Digital Twin using Amazon Alexa. In: Procedia Manufacturing vol. 52 pp. 4–8. Elsevier B.V. ???. https://doi.org/10.1016/j.promfg.2020.11.002 . https://linkinghub.elsevier.com/retrieve/pii/S2351978920321430
Silber-Varod V, Winer A, Geri N (2017) Opening the Knowledge Dam: Speech Recognition for Video Search. J Comput Inf Syst 57(2):106–111. https://doi.org/10.1080/08874417.2016.1183423
Baevski A, Mohamed A (2020) Effectiveness of Self-Supervised Pre-Training for ASR. In: ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) pp. 7694–7698. IEEE ???. https://doi.org/10.1109/ICASSP40776.2020.9054224 . https://ieeexplore.ieee.org/document/9054224/
Sadhu S, He D, Huang C.-W, Mallidi S.H, Wu M, Rastrow A, Stolcke A, Droppo J, Maas R: Wav2vec-C: A Self-supervised Model for Speech Representation Learning 1–19 (2021) arXiv:2103.08393
Soh KW, Loo JHY (2020) A review of Mandarin speech recognition test materials for use in Singapore. Int J Audiol 1–13. https://doi.org/10.1080/14992027.2020.1826587
Song Z (2020) English speech recognition based on deep learning with multiple features. Computing 102(3):663–682. https://doi.org/10.1007/s00607-019-00753-0
Hernandez F, Nguyen V, Ghannay S, Tomashenko N, Estéve Y: TED-LIUM 3: Twice as Much Data and Corpus Repartition for Experiments on Speaker Adaptation. In: Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) pp. 198–208. Springer ??? (2018). https://doi.org/10.1007/978-3-319-99579-3_21 . http://link.springer.com/10.1007/978-3-319-99579-3_21
Suresh Kumar P, Behera HS, K AK, Nayak J, Naik B, (2020) Advancement from neural networks to deep learning in software effort estimation: Perspective of two decades. Computer Science Review 38:100288. https://doi.org/10.1016/j.cosrev.2020.100288
Syiem B, Singh LJ (2021) Exploring end-to-end framework towards Khasi speech recognition system. International Journal of Speech Technology 24(2):419–424. https://doi.org/10.1007/s10772-021-09811-5
Carlini N, Wagner D: Audio Adversarial Examples: Targeted Attacks on Speech-to-Text. In: 2018 IEEE Security and Privacy Workshops (SPW) pp. 1–7. IEEE ??? (2018). https://doi.org/10.1109/SPW.2018.00009 . https://ieeexplore.ieee.org/document/8424625/
Kumar Y, Singh N, Kumar M, Singh A: AutoSSR: an efficient approach for automatic spontaneous speech recognition model for the Punjabi Language. Soft Computing 25(2): 1617–1630 (2021). https://doi.org/10.1007/s00500-020-05248-1
Tóth L (2015) Phone recognition with hierarchical convolutional deep maxout networks. EURASIP Journal on Audio, Speech, and Music Processing 25(1):1–13. https://doi.org/10.1186/s13636-015-0068-3
Tripathi K, Rao KS (2018) Improvement of phone recognition accuracy using speech mode classification. International Journal of Speech Technology 21(3):489–500. https://doi.org/10.1007/s10772-017-9483-4
Caranica A, Cucu H, Buzo A, Burileanu C: On the design of an automatic speech recognition system for Romanian language. Control Engineering and Applied Informatics 18(2): 65–76 (2016)
Tu Y-H, Du J, Lee C-H (2018) A Speaker-Dependent Approach to Single-Channel Joint Speech Separation and Acoustic Modeling Based on Deep Neural Networks for Robust Recognition of Multi-Talker Speech. Journal of Signal Processing Systems 90(7):963–973. https://doi.org/10.1007/s11265-017-1295-x
Tu Y-H, Du J, Sun L, Ma F, Wang H-K, Chen J-D, Lee C-H (2019) An iterative mask estimation approach to deep learning based multi-channel speech recognition. Speech Communication 106 (2018):31–43. https://doi.org/10.1016/j.specom.2018.11.005
Ueda Y, Wang L, Kai A, Ren B (2015) Environment-dependent denoising autoencoder for distant-talking speech recognition. EURASIP Journal on Advances in Signal Processing 92(1):1–11. https://doi.org/10.1186/s13634-015-0278-y
Uma Maheswari S, Shahina A, Nayeemulla Khan A (2021) Understanding Lombard speech: a review of compensation techniques towards improving speech based recognition systems. Artif Intell Rev 54(4):2495–2523. https://doi.org/10.1007/s10462-020-09907-5
Veisi H, Haji Mani A (2020) Persian speech recognition using deep learning. International Journal of Speech Technology 23(4):893–905. https://doi.org/10.1007/s10772-020-09768-x
Wang J (2020) Speech recognition in English cultural promotion via recurrent neural network. Pers Ubiquit Comput 24(2):237–246. https://doi.org/10.1007/s00779-019-01293-2
Wang X, Xu L (2021) Speech perception in noise: Masking and unmasking. J Otol 16(2):1–11. https://doi.org/10.1016/j.joto.2020.12.001
Wang Q, Feng C, Xu Y, Zhong H, Sheng VS (2020) A novel privacy-preserving speech recognition framework using bidirectional LSTM. Journal of Cloud Computing 9(1):36. https://doi.org/10.1186/s13677-020-00186-7
Wang D, Zhang Y, Xin J (2020) An emergent deep developmental model for auditory learning. Journal of Experimental and Theoretical Artificial Intelligence 32(4):665–684. https://doi.org/10.1080/0952813X.2019.1672795
Kang J, Zhang W.-Q, Liu W.-W, Liu J, Johnson M.T: Lattice Based Transcription Loss for End-to-End Speech Recognition. Journal of Signal Processing Systems 90(7): 1013–1023 (2018). https://doi.org/10.1007/s11265-017-1292-0
Qian Y.-m, Xiang X: Binary neural networks for speech recognition. Frontiers of Information Technology and Electronic Engineering 20(5): 701–715 (2019). https://doi.org/10.1631/FITEE.1800469
Ying W, Zhang L, Deng H (2020) Sichuan dialect speech recognition with deep LSTM network. Frontiers of Computer Science 14(2):378–387. https://doi.org/10.1007/s11704-018-8030-z
Qian Y, Hu H, Tan T (2019) Data augmentation using generative adversarial networks for robust speech recognition. Speech Communication 114(January): 1–9. https://doi.org/10.1016/j.specom.2019.08.006
Frihia H, Bahi H (2016) Embedded Learning Segmentation Approach for Arabic Speech Recognition. In: Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) vol. 9924 LNCS pp. 383–390. Springer ???. https://doi.org/10.1007/978-3-319-45510-5_44 . http://link.springer.com/10.1007/978-3-319-45510-5_44
Zhang Y, Zhang P, Yan Y (2019) Language Model Score Regularization for Speech Recognition. Chin J Electron 28(3):604–609. https://doi.org/10.1049/cje.2019.03.015
Zhang X, Zhao Y, Xie J, Li C, Hu Z (2020) Geological big data acquisition based on speech recognition. Multimedia Tools and Applications 79(33–34):24413–24428. https://doi.org/10.1007/s11042-020-09064-5
Kim S, Bae S, Won C (2021) Open-source toolkit for end-to-end Korean speech recognition. Software Impacts 7, 1–4. https://doi.org/10.1016/j.simpa.2021.100054
Zhong X, Dai Y, Dai Y, Jin T (2018) Study on processing of wavelet speech denoising in speech recognition system. International Journal of Speech Technology 21(3):563–569. https://doi.org/10.1007/s10772-018-9516-7
Zhong J, Zhang P, Li X (2019) Adaptive recognition of different accents conversations based on convolutional neural network. Multimedia Tools and Applications 78(21):30749–30767. https://doi.org/10.1007/s11042-018-6590-4
Zhou P, Jiang H, Dai L-R, Hu Y, Liu Q-F (2015) State-Clustering Based Multiple Deep Neural Networks Modeling Approach for Speech Recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing 23(4):1–11. https://doi.org/10.1109/TASLP.2015.2392944
Zhu T, Cheng C (2020) Joint CTC-Attention End-to-End Speech Recognition with a Triangle Recurrent Neural Network Encoder. Journal of Shanghai Jiaotong University (Science) 25(1):70–75. https://doi.org/10.1007/s12204-019-2147-6
Zia T, Zahid U (2019) Long short-term memory recurrent neural network architectures for Urdu acoustic modeling. International Journal of Speech Technology 22(1):21–30. https://doi.org/10.1007/s10772-018-09573-7
Zoughi T, Homayounpour MM (2019) A Gender-Aware Deep Neural Network Structure for Speech Recognition. Iranian Journal of Science and Technology, Transactions of Electrical Engineering 43(3):1–10. https://doi.org/10.1007/s40998-019-00177-8
Zoughi T, Homayounpour MM, Deypir M (2020) Adaptive windows multiple deep residual networks for speech recognition. Expert Systems with Applications 139:1–16. https://doi.org/10.1016/j.eswa.2019.112840
Download references
This is supported by the Department of Science and Technology, under the Scheme for Young Scientists & Technologists (SYST), by the Government of India [SP/YO/382/2018(G)]
Author information
Authors and affiliations.
Department of Computer Science, Punjabi University, Rajpura Road, Patiala, 147001, Punjab, India
Amandeep Singh Dhanjal
Department of Computer Science and Engineering, Punjabi University, Rajpura Road, Patiala, 147001, Punjab, India
Williamjeet Singh
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Amandeep Singh Dhanjal .
Ethics declarations
Conflicts of interest/competing interests.
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Dhanjal, A.S., Singh, W. A comprehensive survey on automatic speech recognition using neural networks. Multimed Tools Appl 83 , 23367–23412 (2024). https://doi.org/10.1007/s11042-023-16438-y
Download citation
Received : 22 December 2022
Revised : 31 May 2023
Accepted : 28 July 2023
Published : 15 August 2023
Issue Date : March 2024
DOI : https://doi.org/10.1007/s11042-023-16438-y
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Speech recognition
- Neural network
- Deep learning
- Find a journal
- Publish with us
- Track your research
IMAGES
VIDEO
COMMENTS
A huge amount of research has been done in the field of speech signal processing in recent years. In particular, there has been increasing interest in the automatic speech recognition (ASR) technology field. ASR began with simple systems that responded to a limited number of sounds and has evolved into sophisticated systems that respond fluently to natural language. This systematic review of ...
ASR can be defined as the process of deriving the. transcription of speech, known as a word sequence, in which. the focus is on the shape of the speech wave [1]. In actuality, speech recognition ...
Speech emotion recognition (SER), a sub-discipline of affective computing (Picard, 2000), has been around for more than two decades and has led to a considerable amount of published works (Akçay & Oğuz, 2020; Gadhe & Deshmukh, 2015).SER involves recognizing the emotional aspects of speech irrespective of the semantic content (Lech et al., 2020).A typical SER system can be considered as a ...
During the last decade, Speech Emotion Recognition (SER) has emerged as an integral component within Human-computer Interaction (HCI) and other high-end speech processing systems. Generally, an SER system targets the speaker's existence of varied emotions by extracting and classifying the prominent features from a preprocessed speech signal. However, the way humans and machines recognize and ...
Abstract page for arXiv paper 2111.01690: Recent Advances in End-to-End Automatic Speech Recognition. ... 2 Nov 2021 15:49:20 UTC (6,878 KB) [v2] Wed, 2 Feb 2022 23:38:10 UTC (6,908 KB) Full-text links: Access Paper: View a PDF of the paper titled Recent Advances in End-to-End Automatic Speech Recognition, by Jinyu Li. View PDF;
1. Introduction. Automatic Speech Recognition (ASR) converts speech signals to corresponding text via algorithms. This paper examines the history of ASR research, exploring why many ASR design choices were made, how ASR is currently done, and which changes may achieve significantly better results.
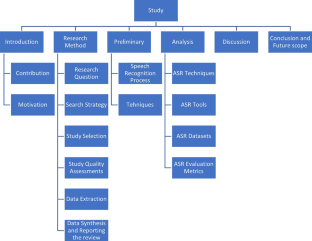
A total of 60 primary research papers spanning from 2011 to 2023 were reviewed to investigate, interpret, and analyze the related literature by addressing five key research questions. ... Seknedy, M. E., & Fawzi, S. (2021). Speech emotion recognition system for human interaction applications. In 10th international conference on intelligent ...
AbstractConventional automatic speech recognition (ASR) and emerging end-to-end (E2E) speech recognition have achieved promising results after being provided with sufficient resources. However, for low-resource language, the current ASR is still challenging. The Lhasa dialect is the most widespread Tibetan dialect and has a wealth of speakers ...
The analysis of the research articles published between 2015 to 2021 in this research field, allows us to provide an overview of the most frequently used tools for neural network-based speech recognition systems. there are various open-source toolkits present for developing the speech recognition model.It has been observed from the Fig. 6. that ...
Nowadays emotion recognition from speech (SER) is a demanding research area for researchers because of its wide real-life applications. ... The focus of this review is on DL approaches for SER. A total of 152 papers have been reviewed from years 2000-2021. We have identified frequently used speech databases and related accuracies achieved ...